Design considerations
Data latency
Data throughput
Data freshness
-
Transient data
- Elasticache
- DynamoDB DAX
-
Persistent data
-
Hot
- DynamoDB
-
Warm
- RDS
-
Cold
- Glacier
-
Data access patterns
- Index selection
Message ordering
Delivery guarantee
- At most once
- At least once
- Exactly once
Fault tolerance
Availability
Data Lineage
Data lineageis one of the most critical components of a data governance strategy for data lakes.Data lineagehelps ensure that accurate, complete and trustworthy data is being used to drive business decisions.- While a data catalog provides metadata management features and search capabilities,
data lineageshows the full context of your data by capturing in greater detail the true relationships between data sources, where the data originated from and how it gets transformed and converged.
DBMS
OLTP
-
Key points
- Operational data stored in a
row-based format - Smaller compute size
- Low latency
- High throughput
- High concurrency
- High change velocity
- Usually a good fit for
caching - Mission-critical,
HA,DR, data protection
- Operational data stored in a
-
Takeaway
- Mainly
Create,Update,Deleteoperations
- Mainly
-
Characteristics
-
Typical applications are characterized by heavy OLTP transaction volumes. OLTP transactions;
- are short-lived (i.e., no user stalls)
- touch small amounts of data per transaction
- use indexed lookups (no table scans)
- have a small number of forms (a small number of queries with different arguments)
-
-
Databases
-
SQL (RDBMS)
-
Designing Highly Scalable Database Architectures (opens in a new tab)
Common OLTP RDBMS architecture design choices
-
-
NewSQL
-
Pros
- Horizontally scalable like NoSQL
- SQL query interface like traditional RDBMS
- ACID like traditional RDBMS
-
Products
- CockroachDB
-
-
OLAP
-
Key points
- Analytic data commonly stored in a
columnar format - Datasets are large and use
partitioning Largecompute size- Regularly performs
complex joins and aggregations - Bulk loading or trickle inserts
- Low change velocity
- Analytic data commonly stored in a
-
Resources
-
Takeaway
- Mainly
Readoperation
- Mainly
-
Product
-
ClickHouse
Cons
- Query performance on joined tables
-
Apache Doris
-
Apache Druid
-
Apache Pinot
-
DBMS - Concepts
CAP Theorem
-
Concepts
-
A distributed system is a network that stores data on more than one node (physical or virtual machines) at the same time.
-
Consistency
- All clients see the same data at the same time, no matter which node they connect to.
- Not
ACIDconsistency
-
Availability
- Any client making a request for data gets a response, even if one or more nodes are down.
-
Partition tolerance
- The cluster must continue to work despite any number of communication breakdowns between nodes in the system.
-
Resources
-
-
NoSQL databases
-
CP databases
-
MongoDB
- MongoDB is a single-master system, and each replica set can have only one primary node that receives all the write operations.
-
-
AP databases
-
Cassandra
- Cassandra doesn't have a master node, and provides
eventual consistencyby allowing clients to write to any nodes at any time and reconciling inconsistencies as quickly as possible.
- Cassandra doesn't have a master node, and provides
-
-
CA databases
- Not practical and does not exist in reality
-
Column-oriented Database
- In a
row-oriented system, indices mapcolumn valuestorowids, whereas in acolumn-oriented system, columns maprowidstocolumn values.
Data Ingestion
Apache NiFi (opens in a new tab)
Change Data Capture (CDC)
-
Implementations
-
Query-based CDC
-
✅ Usually easier to set up
It's just a JDBC connection to your database, just like running a JDBC query from your application or favorite database dev tool.
-
✅ Requires fewer permissions
You're only querying the database, so you just need a regular read-only user with access to the tables.
-
🛑 Requires specific columns in source schema to track changes
If you don't have the option to modify the schema to include a timestamp or incrementing ID field, then life becomes somewhat difficult.
-
🛑 Impact of polling the database (or higher-latencies trade-off)
If you run the same query too often against the database you're going to (quite rightly) have your DBA on the phone asking what's going on. But set the polling too infrequently, and you end up with data that is potentially less useful because of its age.
-
🛑 Can't track DELETEs
You can only query a relational database for data that's there right now. If the data's been deleted, you can't query it, and so you can't capture those events into Apache Kafka.
-
🛑 Can't track multiple events between polling interval
If a row changes several times during the period in which the connector polls, you'll only capture the latest state. In some cases, this may not matter (if you just want the latest state of a table). In others, it can matter a lot (if you're building applications that are driven by changes happening in the database).
-
-
Log-based CDC
-
✅ Greater data fidelity
Everything is captured—inserts, updates, and even DELETEs. For each of these, we can also get the previous state of the row that changed.
-
✅ Lower latency and lower impact on the source database
Because we're not polling the database but reading the transaction log, it's lower latency, and we're putting less load on the database too.
-
🛑 More setup steps and higher system privileges required
The transaction log is a relatively low-level component of the database, so we need greater privileges in the database to access the API for it, and it can be more complicated to set up.
-
-
-
Microservices
- Event sourcing pattern
- CQRS pattern
- Materialized View pattern
-
Resources
-
Log-based CDC solution built on Kafka
-
Database algorithms
Write-ahead Logging (WAL)
- Append only logging on disk to provide atomicity and durability
- All modifications are written to a
transaction logbefore they are applied. - In the event of a failure, either committed modifications are rolled back, or uncommitted ones are applied to ensure consistency.
- WAL can be used to implement CDC.
Caching Strategies
Caching Patterns
Cache-Aside / Lazy Loading (reactive approach)
-
Key points
- Updated when the data is requested
- Suitable for infrequently accessed data
-
Pros
- Cache size cost-effective
-
Cons
- Cache miss penalty, more latency for the initial response
Write-Through (proactive approach)
-
Key points
- Updated immediately when the DB is updated
- Suitable for frequently accessed data
-
Pros
- Cache miss less likely, less latency
-
Cons
- More space wasted in the cache for infrequently accessed data
Cache Validity
- Evaluate the rate of change of the data
- Evaluate the risk of using stale data
- Evaluate DB activity pattern to determine the timing to update cache, to avoid burdening DB further
- Determine and apply TTL to ensure data is not stale
Cache Evictions
-
Evictions occur when cache memory is overfilled or is greater than the maxmemory setting for the cache, causing the engine to select keys to evict to manage its memory.
-
Evictions could indicate that the cache node needs to be scaled up or out to accommodate more data.
-
Policies
- LRU (Least Recently Used)
- LFU (Least Frequently Used)
- Random
Data File Formats
Apache ORC
Apache Parquet
Data Lakes
Open Table Formats
Apache Iceberg
-
Features
- Transactional consistency between multiple applications where files can be added, removed or modified atomically, with full read isolation and multiple concurrent writes
- Full schema evolution to track changes to a table over time
- Time travel to query historical data and verify changes between updates
- Partition layout and evolution enabling updates to partition schemes as queries and data volumes change without relying on hidden partitions or physical directories
- Rollback to prior versions to quickly correct issues and return tables to a known good state
- Advanced planning and filtering capabilities for high performance on large data volumes
-
Metadata
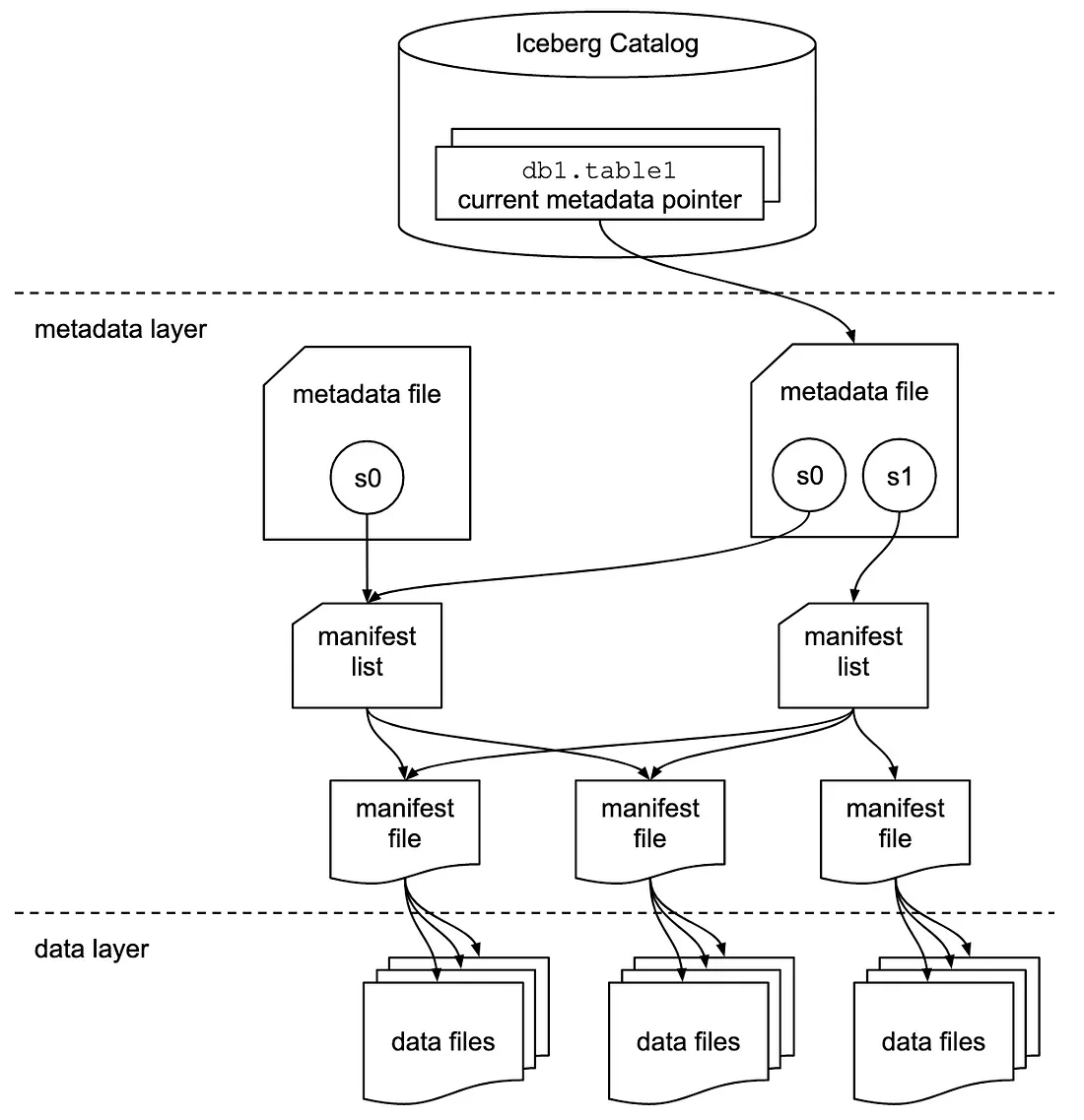
-
Usage patterns
-
Insights
- Great for slowly changing big datasets (read heavy, write light)
Delta Lake
SQL Query Engine
Trino
- Interactive analytics query engine for big data
Database
Database - Data Structures
-
LSM
-
LSM databases — An Overview: The DB for write heavy workloads (opens in a new tab)
-
Examples
- Apache HBase
- Apache Cassandra
- LevelDB
- ScyllaDB